Sie zerlegt einen Fall um parallel abgearbeitet zu werden, dazu bedient sich diese des MPI - Protokolls, entwerder OpenMPI oder MicrosoftMPI, je nach Ihrer Wahl.
Dazu muss ein Dictionary namens decomposeParDict im Systemunterverzeichnis des Falls (im Systemverzeichnis - case, des OpenFOAM-Projektverzeichnisses) vorhanden sein.
In der DecomposeParDict werden Angaben zur Zerlegung von Flächen und der Parallelisierung dieser Aufgabe gemacht.
Die DecomposeParDict kann auf mehrere Rechner verteilt werden.
Prozessoren gibt die Anzahl der Prozessoren (oder Kerne) an, die Sie zur Lösung Ihres Falls verwenden möchten.
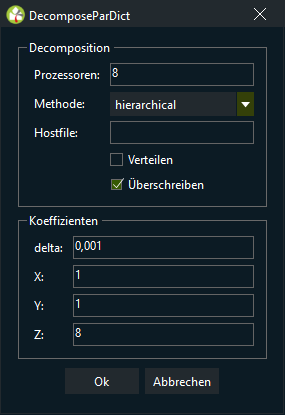
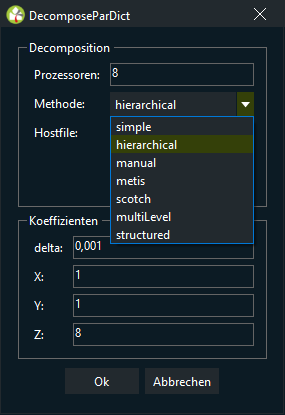
In der Auswahlliste Method geben Sie die zur Zerlegung der Domäne verwendete Methode an.
Verfügbare Methoden sind:
| simple | Diese Methode zerlegt die Domäne zu gleichen Teilen gemäß den im entsprechenden Subdictionary simpleCoeffs angegebenen Richtungen. Zum Beispiel: Zerlegen Sie einen Fall in 4 Teile in der x-Richtung, n muss auf (4 1 1) gesetzt werden. Um die Domäne in 8 Teile zu zerlegen, 4 in der x-Richtung und 2 in der z-Richtung, muss n auf (4 1 2) gesetzt werden. |
| hierarchical | Hierarchisch ist dasselbe wie simple, aber der Benutzer kann die Reihenfolge angeben, nach der die Zerlegung durchgeführt wird. |
| manual | Manuell erlaubt dem Benutzer, direkt die Zuordnung jeder Zelle zu einem bestimmten Prozessor zu spezifizieren. |
| metis | Metis zerlegt die Domäne mit Hilfe des METIS-Algorithmus, der versucht, die Kommunikation zwischen den Prozessoren zu minimieren. Es ist möglich, Gewichte für die verschiedenen Prozessoren anzugeben, wenn das parallelisierte System aus Maschinen mit unterschiedlichen Leistungen zusammengesetzt ist. |
| scotch | Bei paralleler Ausführung wird der gesamte Graph auf dem Master gesammelt, zerlegt und zurückgeschickt. Verwenden Sie ptscotchDecomp für eine korrekte verteilte Zerlegung. |
| multiLevel | Unterschiedliche Zerlegungsmethoden, die der Reihe nach anzuwenden sind. Dies ist wie hierarchisch, aber völlig allgemein - jede Methode kann auf jeder Ebene angewendet werden. |
| structured | Flächen zur Durchführung der 2D-Zerlegung. Nur bei strukturierten Netzen, die Zellen müssen in 'Spalten' auf den Flächen liegen. |
Ein zerlegter OpenFOAM-Fall wird parallel von MPI ausgeführt.
MPI kann sehr einfach auf einer lokalen Multiprozessor-Maschine ausgeführt werden, aber wenn es auf Maschinen über ein Netzwerk läuft, muss eine Datei erstellt werden, die die Hostnamen der Maschinen enthält.
Die Datei kann einen beliebigen Namen erhalten und sich in einem beliebigen Pfad befinden. In der folgenden Beschreibung beziehen wir uns auf eine solche Datei durch den generischen Namen, einschließlich des vollständigen Pfades, <Maschinen>.
Die Datei <Maschinen> enthält die Namen der Maschinen, pro Zeile ist eine Maschine aufgeführt.
Die Namen müssen einem vollständig aufgelösten Hostnamen in der Datei /etc/hosts der Maschine entsprechen, auf der das MPI ausgeführt wird.
Die Liste muss den Namen der Maschine enthalten, auf der MPI ausgeführt wird. Wenn ein Rechnerknoten mehr als einen Prozessor enthält, kann dem Knotennamen der Eintrag cpu=n folgen, wobei n die Anzahl der Prozessoren ist, die MPI auf diesem Knoten nutzen soll.
Stellen wir uns zum Beispiel vor, ein Benutzer möchte MPI von Rechner aaa auf den folgenden Rechnern laufen lassen: aaa; bbb, der 2 Prozessoren hat; und ccc.
Die Datei <Maschinen> würde so aussehen:
aaa
bbb cpu=2
ccc
Es kann sein, dass Datendateien verteilt werden müssen, wenn z.B. nur lokale Platten verwendet werden, um die Leistung zu verbessern. In diesem Fall kann der Benutzer feststellen, dass der Wurzelpfad zum Fallverzeichnis von Rechner zu Rechner unterschiedlich sein kann. Die Pfade müssen dann im decomposeParDict-Dictionary unter Verwendung der Schlüsselwörter distributed und roots angegeben werden. Der verteilte Eintrag sollte lauten:
distributed yes;
und der Wurzeleintrag ist eine Liste von Wurzelpfaden, <root0>, <root1>, ..., für jeden Knoten
roots
<nroots>
(
"<rootl0>"
"<root1>"
…
);
wobei <nRoots> die Anzahl der Wurzeln ist.
Jedes der Verzeichnisse processor<N> sollte im Verzeichnis case an jedem der im decomposeParDict-Dictionary angegebenen Wurzelpfade platziert werden. Das Systemverzeichnis und die Dateien innerhalb des Konstantenverzeichnisses (const im OpenFOAM-Systemverzeichnis) müssen ebenfalls in jedem Fallverzeichnis vorhanden sein.
Anmerkung: Die Dateien im Konstanten-Verzeichnis werden benötigt, das PolyMesh-Verzeichnis jedoch nicht.
Nachdem ein Fall parallel bearbeitet wurde, kann er zur Nachbearbeitung rekonstruiert werden. Der Fall wird rekonstruiert, indem die Mengen der Zeitverzeichnisse von jedem Prozessor <N> Verzeichnis zu einer einzigen Menge von Zeitverzeichnissen zusammengeführt werden. Das Dienstprogramm reconstructPar führt eine solche Rekonstruktion durch, indem es den Befehl ausführt:
rekonstruierenPar
Wenn die Daten auf mehrere Platten verteilt sind, müssen sie zur Rekonstruktion zunächst in das lokale Fallverzeichnis kopiert werden, die verteilten Verzeichnisse werden dabei überschrieben.
| delta | Delta ist der Schräglauffaktor der Zelle. Sein Standardwert ist 0,001. |
| X | Die Zahl der zu zerlegenden Teile eines Falls in X-Richtung. |
| Y | Die Zahl der zu zerlegenden Teile eines Falls in Y-Richtung. |
| Z | Die Zahl der zu zerlegenden Teile eines Falls in Z-Richtung. |
